Файл Robots.txt
- Що можна очікувати від цієї статті У цій статті пояснюється, що таке файл robots.txt і як його можна...
- Синоніми для
- Чому важливий файл robots.txt?
- Ваша робота robots.txt працює проти вас?
- Це виглядає як файл?
- Агент користувача у файлі robots.txt
- Заборонити в robots.txt
- Дозволити в файлі robots.txt
- Використання шаблону *
- Вкажіть кінець URL-адреси за допомогою $
- Мапа сайту в файлі robots.txt
- Зауваження
- Затримка сканування в файлі robots.txt
- Bing, Yahoo і Яндекс
- Baidu
- Коли мені потрібен файл robots.txt?
- Кращі методи для файлу robots.txt
- Порядок вказівок
- Тільки одна група з рекомендаціями на робота
- Будьте максимально конкретними
- У той же час визначте керівні принципи, призначені для всіх роботів і керівних принципів, призначених...
- Файл Robots.txt для кожного (під) домену.
- Суперечливі вказівки: robots.txt проти Консоль пошуку Google
- Перевірте файл robots.txt після запуску
- Не використовуйте noindex у файлі robots.txt
- Приклади файлів robots.txt
- Всі роботи мають доступ до всього веб-сайту
- Немає доступу для всіх роботів
- Немає доступу для всіх ботів Google
- Немає доступу до всіх ботів Google, крім новин Googlebot
- Немає доступу для Googlebot і Slurp
- Немає доступу до двох каталогів для всіх роботів
- Немає доступу до одного конкретного файлу для всіх роботів
- Немає доступу до / admin / для Googlebot та / private / для Slurp
- Robots.txt для WordPress
- Які обмеження robots.txt?
- Сторінки все ще відображаються в результатах пошуку
- Кешування
- Розмір файлу
- Часті питання про Opent
- 1. Чи можна використовувати файл robots.txt, щоб запобігти відображенню сторінок на сторінках результатів...
- 2. Чи потрібно бути обережним з файлом robots.txt?
- 3. Чи заборонено ігнорувати файл robots.txt під час сканування веб-сайту?
- 4. У мене немає файлу robots.txt. Чи скануються пошукові системи мого веб-сайту?
- 5. Чи можу я використовувати Noindex у файлі robots.txt замість Disallow?
- 6. Які пошукові системи підтримують файл robots.txt?
- 7. Як запобігти індексації пошуковими системами результатів пошуку на моєму веб-сайті WordPress?
Що можна очікувати від цієї статті
У цій статті пояснюється, що таке файл robots.txt і як його можна ефективно використовувати:
- Пошукові системи забороняють доступ до певних частин вашого веб-сайту
- Уникайте дублювання вмісту
- Зробіть пошукові системи більш ефективним скануванням вашого сайту.
Що таке файл robots.txt?
Файл robots.txt передає правила обробки вашого веб-сайту для пошукових систем.
Перш ніж пошукова система відвідає звичайні сторінки на вашому веб-сайті, вона спочатку намагається отримати файл robots.txt, щоб дізнатися, чи існують спеціальні інструкції для сканування вашого веб-сайту. Ми називаємо ці вказівки 'інструкціям'.
Якщо файл robots.txt не присутній або якщо не визначено відповідних інструкцій, пошукові системи припускають, що вони можуть сканувати весь веб-сайт.
Хоча всі основні пошукові системи поважають файл robots.txt, пошукові системи все одно можуть ігнорувати файл robots.txt або певні його частини. Тому важливо розуміти, що файл robots.txt є лише набором керівних принципів, а не мандатом.
Синоніми для
Файл robots.txt також називається протоколом виключення роботів, стандартом виключення роботів або протоколом robots.txt .
Чому важливий файл robots.txt?
Файл robots.txt дуже важливий з точки зору пошукової оптимізації (SEO). Він повідомляє пошуковим системам, як вони можуть краще сканувати ваш сайт.
За допомогою файлу robots.txt ви можете заборонити пошуковим системам отримувати доступ до певних частин вашого веб-сайту, запобігати дублюванню проблем із вмістом та вказувати пошуковим системам, як вони можуть ефективніше сканувати ваш сайт .
Приклад
Візьмемо наступну ситуацію як приклад:
Ви керуєте веб-сайтом електронної комерції, на якому відвідувачі з фільтром можуть легко шукати продукти. Однак цей фільтр генерує сторінки, які містять майже той самий вміст, що й інші сторінки. Цей фільтр дуже корисний для відвідувачів, але є незрозумілим для пошукових систем, оскільки він викликає дублювання вмісту. Ви хочете, щоб пошукові системи не індексували ці відфільтровані сторінки, а не витрачали час на сканування цих URL-адрес із відфільтрованим вмістом.
Також можна запобігти дублюванню проблем із вмістом канонічний URL або тег мета-роботів, але обидва вони не гарантують, що пошукові системи тільки сканують найважливіші сторінки вашого веб-сайту. Канонічна URL-адреса та тег мета-роботів не перешкоджають пошуковим системам сканувати сторінки , але лише забезпечують, щоб пошукові системи не відображали сторінки в результатах пошуку . Оскільки пошукові системи можуть витрачати лише обмежений час на сканування веб-сайту, переконайтеся, що пошукові системи витрачають цей час на сторінках, які ви хочете відобразити в результатах пошуку.
Ваша робота robots.txt працює проти вас?
Неправильне налаштування файлу robots.txt може негативно вплинути на ваш SEO. Перевірте швидко, якщо це так!
Це виглядає як файл?
Нижче наведено простий приклад того, як файл robots.txt для WordPress може виглядати так:
Агент користувача: * Disallow: / wp-admin /
Структура файлу robots.txt, наведена вище, така:
Агент користувача: агент користувача вказує, для яких пошукових систем призначені рекомендації.
*: Це вказує на те, що рекомендації призначені для всіх пошукових систем.
Заборонити: цей посібник вказує, який вміст недоступний агенту користувача.
/ wp-admin /: Це шлях, який недоступний агенту користувача.
Підсумок: цей файл robots.txt повідомляє всім пошуковим системам, що каталог / wp-admin / не доступний для них.
Агент користувача у файлі robots.txt
Кожна пошукова система повинна ідентифікувати себе з так званим агентом користувача. Наприклад, роботи Google ідентифікують себе як робот Googlebot, роботів Yahoo як Slurp, а роботів Bing як BingBot і так далі.
Агент користувача повідомляє про початок ряду вказівок. Рекомендації, що містяться між першим користувальницьким агентом і наступним користувальницьким агентом, використовуються в якості керівництва першим агентом користувача.
Настанови можуть бути спрямовані на конкретні агенти користувачів, але можуть також застосовуватися до всіх агентів користувачів. В останньому випадку ми використовуємо наступні символи: User-agent: *.
Заборонити в robots.txt
Заборонити пошуковим системам доступу до певних файлів, розділів або сторінок вашого веб-сайту за допомогою Директиви про заборону. Після директиви Disallow вказано шлях, який недоступний. Якщо не визначено жодного шляху, орієнтир ігнорується.
Приклад
Агент користувача: * Disallow: / wp-admin /
Наведений вище приклад забороняє всім пошуковим системам звертатися до каталогу / wp-admin /.
Дозволити в файлі robots.txt
Директива Allow робить протилежну директиві Disallow і підтримується лише Google і Bing. Використовуючи вказівки "Дозволити і заборонити", ви можете надати пошуковим системам доступ до певного файлу або сторінки в каталозі, який інакше не був би доступним. Після того, як директива Allow приходить, доступний шлях. Якщо не визначено жодного шляху, орієнтир ігнорується.
Приклад
User-agent: * Дозволити: /media/terms-and-conditions.pdf Заборонити: / media /
Наведений вище приклад забороняє всім пошуковим системам звертатися до каталогу / media /, за винятком доступу до файлу /media/terms-and-conditions.pdf.
Важливо: при одночасному використанні вказівок "Дозволити і заборонити" не вказуйте символи у файлі robots.txt, оскільки це може призвести до конфліктуючих правил.
Приклад конфліктуючих керівних принципів
User-agent: * Дозволити: / каталог Disallow: /*.html
У цьому випадку пошукові системи не знають, що робити з URL-адресою http://www.domein.nl/directory.html. Незрозуміло, що пошукові системи мають доступ до цієї URL-адреси.
Покладіть кожну орієнтир самостійно, оскільки в іншому випадку пошукові системи можуть заплутатися під час аналізу файлу robots.txt.
Тому уникайте файлу robots.txt, як показано нижче:
Користувальницький агент: * Disallow: / directory-1 / Disallow: / directory-2 / Disallow: / directory-3 /
Використання шаблону *
Окрім визначення агента користувача, шаблон також використовується для визначення URL-адрес, які містять певний рядок. Шаблон підписується Google, Bing, Yahoo і Ask ..
Приклад
Агент користувача: * Disallow: / *?
Наведений вище приклад забороняє всім пошуковим системам звертатися до URL-адрес, які містять знак запитання (?).
Вкажіть кінець URL-адреси за допомогою $
Використовуйте знак долара ($) в кінці шляху, щоб вказати кінець URL-адреси.
Приклад
Агент користувача: * Disallow: /*.php$
Наведений вище приклад забороняє всім пошуковим системам звертатися до URL-адрес, які закінчуються на .php.
Мапа сайту в файлі robots.txt
Незважаючи на те, що файл robots.txt призначений для того, щоб вказувати пошуковим системам, які сторінки їм заборонено сканувати , його також можна використовувати для перенаправлення пошукових систем до XML-карти сайту. Це підтримується Google, Bing, Yahoo і Ask.
Карта сайту XML повинна бути включена до файлу robots.txt як абсолютна URL-адреса. URL-адреса не повинна запускатися на тому ж хості , що й файл robots.txt. Як найкраща практика, ми завжди рекомендуємо посилатися на карту сайту XML з файлу robots.txt, навіть якщо ви вже подали XML-карту сайту вручну в Пошуковій консолі Google або Bing Webmaster Tools. Пам'ятайте, що існує більше пошукових систем.
Зауважте, що у файлі robots.txt можна посилатися на декілька XML-мапи сайту.
Приклади
Кілька Sitemap XML:
Агент користувача: * Disallow: / wp-admin / Sitemap: https://www.example.com/sitemap1.xml Карта сайту: https://www.example.com/sitemap2.xml
Наведений вище приклад забороняє всім пошуковим системам доступ до каталогу / wp-admin / і посилається на два XML-мапи сайту: https://www.example.com/sitemap1.xml
і https://www.example.com/sitemap2.xml.
Одномісний файл Sitemap XML:
Агент користувача: * Disallow: / wp-admin / Sitemap: https://www.example.com/sitemap_index.xml
Наведений вище приклад забороняє всім пошуковим системам звертатися до каталогу / wp-admin / і посилається на карту сайту XML з абсолютним URL-адресою https://www.example.com/sitemap_index.xml.
Зауваження
Коментарі розміщуються після символу "#" і можуть бути розміщені на початку нового рядка, а також після орієнтації на одній лінії. Коментарі призначені лише для використання людиною.
Приклад 1
# Не дозволяє доступ до / wp-admin / каталогу для всіх роботів User-agent: * Disallow: / wp-admin /
Приклад 2
User-agent: * # Застосовується до всіх роботів Disallow: / wp-admin / # Не допускає доступу до каталогу / wp-admin /.
Наведені вище приклади повідомляють однаково.
Затримка сканування в файлі robots.txt
Інструкція Crawl-delay є неофіційною директивою, яка запобігає перевантаженню серверів запитами. Якщо пошукові системи здатні перевантажити сервер, додавання директиви Crawl-delay є лише тимчасовим рішенням. Реальною проблемою є бідна хостинг-платформа, на якій працює ваш сайт. Радимо вирішити цю проблему якомога швидше.
Пошукові системи по-різному мають справу з директивою Crawl-delay. Нижче ми пояснюємо, як з цим займаються найбільші пошукові системи.
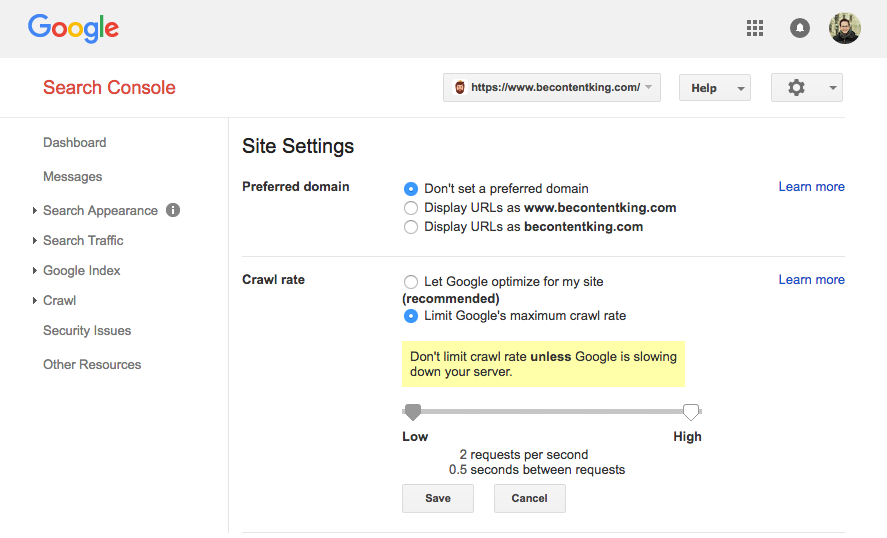
Google не підтримує директиву Crawl-delay. Однак Google має консоль пошуку Google для встановлення швидкості сканування. Щоб встановити швидкість сканування, виконайте наведені нижче дії.
- Увійдіть у консоль пошуку Google.
- Виберіть веб-сайт, для якого потрібно встановити швидкість сканування.
- Натисніть на значок шестерні у верхньому правому куті та виберіть "Налаштування сайту".
- На цьому екрані є можливість встановити швидкість сканування за допомогою повзунка. Швидкість сканування встановлюється за умовчанням "Дозволити Google оптимізувати мій сайт (рекомендовано)".
Bing, Yahoo і Яндекс
Bing, Yahoo і Yandex підтримують посібник Crawl-delay для встановлення максимальної швидкості сканування (див. Документацію для Bing, Yahoo і Yandex). Помістіть орієнтир затримки сканування одразу після рекомендацій Disallow або Allow.
Приклад:
User-agent: BingBot Disallow: / private / Crawl-delay: 10
Baidu
Baidu не підтримує директиву Crawl-delay. Тим не менш, можна встановити швидкість сканування в обліковому записі інструментів для веб-майстрів Baidu. Це працює приблизно так само, як у консолі пошуку Google.
Коли мені потрібен файл robots.txt?
Радимо завжди використовувати файл robots.txt. Додавання файлу robots.txt на ваш веб-сайт не має жодних недоліків, і це ефективний спосіб передавати інструкції пошуковим системам про те, як краще сканувати ваш веб-сайт.
Кращі методи для файлу robots.txt
Завжди розміщуйте файл robots.txt у корені вашого веб-сайту (найвищий каталог хоста) і назвіть ім'я файлу robots.txt, наприклад: https://www.example.com/robots.txt. URL-адреса файлу robots.txt чутлива до регістру, як і будь-яка інша URL-адреса.
Якщо пошукові системи не можуть знайти файл robots.txt у розташуванні за умовчанням, вони припускають, що не існує інструкцій для сканування вашого веб-сайту, і вони сканують все.
Порядок вказівок
Важливо знати, що всі пошукові системи використовують файл robots.txt інакше. За замовчуванням виграє перша орієнтована настанова.
Однак Google і Bing дивляться на специфіку . Наприклад: Дозволити richtlin виграє з директиви Disallow, якщо кількість символів довше.
Приклад
User-agent: * Дозволити: / про компанію / Disallow: / about /
Наведений вище приклад забороняє всім пошуковим системам, включаючи Google і Bing, отримати доступ до каталогу / about /, за винятком каталогу / about / company / sub-directory.
Приклад
Агент користувача: * Disallow: / about / Allow: / про компанію /
Наведений вище приклад забороняє всім пошуковим системам, крім Google і Bing, отримати доступ до каталогу / about /, включаючи / about / company /.
Google і Bing мають доступ, оскільки директива Allow довша, ніж директива Disallow.
Тільки одна група з рекомендаціями на робота
Ви можете визначити лише одну групу керівних принципів для кожної пошукової системи. Включення декількох груп керівних принципів в файлі robots.txt плутаних пошукових системах.
Будьте максимально конкретними
Директива Disallow також працює з частковими угодами. Будьте максимально конкретними при визначенні директиви Disallow, щоб запобігти доступу небажаних пошукових систем до файлів.
Приклад
Агент користувача: * Disallow: / directory
Наведений вище приклад забороняє доступ до пошукових систем до:
/ каталог /
/ directory-name-1
/directory-name.html
/directory-name.php
/directory-name.pdf
У той же час визначте керівні принципи, призначені для всіх роботів і керівних принципів, призначених для певного робота
Якщо керівні принципи для всіх роботів супроводжуються інструкціями для одного конкретного робота, перші згадані вказівки ігноруються спеціально названим роботом. Єдиний спосіб дотримуватися інструкцій робота для всіх роботів полягає в тому, щоб перевизначити їх для конкретного робота.
Давайте подивимося на приклад, який робить це зрозумілим:
Приклад
Агент користувача: * Disallow: / secret / Disallow: / not-started-yet / User-agent: googlebot Disallow: / not-started-yet /
Наведений вище приклад забороняє всім пошуковим системам, крім доступу Google до / secret / і / not-started-yet /. Цей файл robots.txt забороняє доступ Google до / not-launch-yet /, але просто має доступ до / secret /.
Якщо ви не хочете, щоб Googlebot мав доступ до / secret / і / not-started-yet /, повторіть вказівки GoogleBot:
User-agent: * Disallow: / secret / Disallow: / not-started-yet / Користувач-агент: googlebot Disallow: / secret / Disallow: / not-started-yet /
Файл Robots.txt для кожного (під) домену.
Правила у файлі robots.txt застосовуються лише до хосту, де розміщено файл.
Приклади
http://example.com/robots.txt застосовується до http://example.com, але не до http://www.example.com або https://example.com.
Суперечливі вказівки: robots.txt проти Консоль пошуку Google
Якщо правила в файлі robots.txt конфліктують з налаштуваннями, визначеними в консолі пошуку Google, у багатьох випадках Google вибиратиме налаштування, визначені в Пошуковій консолі Google, замість інструкцій у файлі robots.txt файл.
Перевірте файл robots.txt після запуску
Після запуску нових функцій або нового веб-сайту з тестового середовища до виробничого середовища завжди перевіряйте файл robots.txt для Disallow /.
Не використовуйте noindex у файлі robots.txt
Хоча деякі рекомендують використовувати директиву noindex у файлі robots.txt, вона не є офіційним стандартом. Крім того, Google публічно вказав не використовувати його. Незрозуміло, чому, але ми рекомендуємо серйозно приймати їхні рекомендації.
Приклади файлів robots.txt
У цій главі ми наводимо ряд прикладів файлів robots.txt.
Всі роботи мають доступ до всього веб-сайту
Існує кілька способів повідомити пошуковим системам, що вони мають доступ до всього веб-сайту:
Агент користувача: * Disallow:
Or
Маєте порожній файл robots.txt або взагалі не маєте файла robots.txt.
Немає доступу для всіх роботів
Агент користувача: * Disallow: /
Pro tip: додатковий знак може зробити різницю.
Немає доступу для всіх ботів Google
Агент користувача: googlebot Disallow: /
Пам’ятайте, що якщо ви не дозволите Googlebot, це стосується всіх ботів Google. Так само і роботів Google, які шукають новини (googlebot-news) або зображення (googlebot-images).
Немає доступу до всіх ботів Google, крім новин Googlebot
Агент користувача: googlebot Disallow: / User-agent: googlebot-news Disallow:
Немає доступу для Googlebot і Slurp
Агент користувача: Slurp Агент користувача: googlebot Disallow: /
Немає доступу до двох каталогів для всіх роботів
User-agent: * Disallow: / admin / Disallow: / private /
Немає доступу до одного конкретного файлу для всіх роботів
User-agent: * Disallow: /directory/some-pdf.pdf
Немає доступу до / admin / для Googlebot та / private / для Slurp
Агент користувача: googlebot Disallow: / admin / Агент користувача: Slurp Disallow: / private /
Robots.txt для WordPress
Файл robots.txt, наведений нижче, спеціально оптимізований для WordPress.
- Ви не бажаєте сканувати розділ адміністратора.
- Не хочете, щоб ваші внутрішні сторінки результатів пошуку на вашому веб-сайті сканувалися.
- Ви не бажаєте сканувати сторінки архіву тегів і авторів.
- Ви не бажаєте сканувати сторінку 404.
User-agent: * Disallow: / wp-admin / #no доступ до розділу адміністратора. Disallow: /wp-login.php#no доступ до розділу адміністратора. Disallow: / search / #no доступ до внутрішніх сторінок результатів пошуку. Disallow: *? S = * # немає доступу до внутрішніх сторінок результатів пошуку. Disallow: *? P = * #не доступ до сторінок, якщо постійні посилання не працюють. Disallow: * & p = * # немає доступу до сторінок, якщо постійні посилання не працюють. Disallow: * & preview = * #не доступ до сторінок попереднього перегляду. Disallow: / tag / #no доступ до сторінок архіву тегів Disallow: / author / #no доступ до сторінок архіву авторів. Disallow: / 404 error / #no доступ до сторінки 404. Мапа сайту: https://www.example.com/sitemap_index.xml
Примітка: цей файл robots.txt працює в більшості випадків. Однак переконайтеся, що ви завжди коригуєте та застосовуєте його до конкретної ситуації .
Які обмеження robots.txt?
Файл Robots.txt містить правила
Хоча файл robots.txt добре поважається пошуковими системами, він залишається орієнтиром, а не мандатом.
Сторінки все ще відображаються в результатах пошуку
Сторінки, які не доступні пошуковим системам robots.txt, можуть відображатися в результатах пошуку, якщо вони пов'язані зі сканованою сторінкою. Це виглядає так:

Protip: Можна видалити ці URL-адреси з результатів пошуку за допомогою інструмента видалення URL консолі пошуку Google. Пам'ятайте, що Google лише тимчасово видаляє ці URL-адреси. Видаляйте URL-адреси вручну кожні 90 днів, щоб запобігти повторному показу в результатах пошуку.
Кешування
Google вказав, що файл robots.txt зазвичай кешується протягом 24 годин. Пам’ятайте про це під час внесення змін до файлу robots.txt.
Незрозуміло, як інші пошукові системи обробляють кешування файлів robots.txt.
Розмір файлу
Google наразі підтримує максимальний розмір файлу 500 кб для файлів robots.txt. Весь вміст після цього максимуму можна ігнорувати.
Незрозуміло, чи використовують інші пошукові системи максимальний розмір файлу.
Часті питання про Opent
- Чи можна використовувати файл robots.txt, щоб запобігти відображенню сторінок на сторінках результатів пошуку?
- Чи потрібно бути обережним з файлом robots.txt?
- Чи заборонено ігнорувати файл robots.txt під час сканування веб-сайту?
- У мене немає файлу robots.txt. Чи скануються пошукові системи мого веб-сайту?
- Чи можна використовувати Noindex у файлі robots.txt, а не у Disallow?
- Які пошукові системи підтримують файл robots.txt?
- Як запобігти індексації пошуковими системами результатів пошуку на веб-сайті WordPress?
1. Чи можна використовувати файл robots.txt, щоб запобігти відображенню сторінок на сторінках результатів пошуку?
Ні, це буде виглядати так:
Крім того: якщо Google не має доступу до сторінки через файл robots.txt, а сама сторінка містить тег <meta name = "robots" content = "noindex, nofollow">, пошукові системи все одно індексують сторінку. Вони не знають про <meta name = "robots" content = "noindex, nofollow">, оскільки вони не мають доступу до сторінки.
2. Чи потрібно бути обережним з файлом robots.txt?
Так, але не бійтеся використовувати його. Це відмінний інструмент для кращого сканування Вашого веб-сайту Google.
3. Чи заборонено ігнорувати файл robots.txt під час сканування веб-сайту?
Не в теорії. Файл robots.txt є додатковим орієнтиром для пошукових систем. Однак з юридичної точки зору ми не можемо нічого сказати про це. Коли ви сумніваєтеся, отримайте пораду від юриста.
4. У мене немає файлу robots.txt. Чи скануються пошукові системи мого веб-сайту?
Так. Якщо пошукові системи не знаходять файл robots.txt, вони припускають, що немає вказівок, і вони сканують весь веб-сайт.
5. Чи можу я використовувати Noindex у файлі robots.txt замість Disallow?
Ні, ми не рекомендуємо це робити. Google також радить відмовитися від цього .
6. Які пошукові системи підтримують файл robots.txt?
Всі основні пошукові системи підтримують файл robots.txt:
7. Як запобігти індексації пошуковими системами результатів пошуку на моєму веб-сайті WordPress?
Вкажіть такі правила у файлі robots.txt. Це запобігає індексації пошуковими системами цих сторінок, якщо не було внесено жодних змін у роботу сторінок результатів пошуку.
Агент користувача: * Disallow: /? S = Disallow: / search /
Докладніше про robots.txt:
Txt?Txt працює проти вас?
Це виглядає як файл?
Txt?
Txt?
Txt?
Txt під час сканування веб-сайту?
Чи скануються пошукові системи мого веб-сайту?
Txt замість Disallow?
Txt?