Вибираємо html-парсер для JMeter
- Опис проекту
- об'єкт тестування
- основа тестування
- Core improvements
- Protocols and Load Testing improvements
- Incompatible changes
- Improvements
- цілі тестування
- стратегія
- Підхід до тестування
- результати
- Сайти з малою кількістю контенту - хороший результат
- Сайти з великою кількістю контенту - поганий результат
- Кількість підзапитів при використанні різних парсеров
- Середня якість роботи парсеров
- Детальний аналіз пропущених посилань при роботі Apache.JMeter 3.0 сайта habrahabr.ru
- Список і їх обробка
- звіти WebPageTest.org
- Список Apache.JMeter
- Автоматизація обробки балок
- Рекурсивна завантаження на yandex.ru
- Склад проекту
- Файл test.bat з основними настройками тесту
- висновки
Пропоную:
- оцінити повноту вилучення посилань на html-ресурси в Apache.JMeter;
- перевірити чи правда витяг посилань в Apache.JMeter 3.0 стало повнішим;
- випробувати в справі плагін CsvLogWriter .
Як говорить народна мудрість: «Вірити вір, але перевір».
Опис проекту
Коли JMeter 3.0 був ще в розробці, колеги і я тестували його і почали застосовувати в роботі. Першим в бойовому тестуванні застосував нову версію Артем Федоров для однієї з нових послуг https://pgu.mos.ru, де при використанні JMeter 3.0 якість розбору вбудованих ресурсів значно покращився у порівнянні з попередньою версією.
І тут постало питання, а як це якість, як його виміряти для різних сайтів, яким воно було і яким стало?
Матеріали і результати дослідження відображені в поточній статті.
об'єкт тестування
Тестуються htmlParser-и для JMeter 2.13 і JMeter 3.0.
Парсери Apache.JMeter 2.13:
- LagartoBasedHtmlParser;
- HtmlParserHTMLParser;
- JTidyHTMLParser;
- RegexpHTMLParser;
- JsoupBasedHtmlParser.
Парсеси Apache.JMeter 3.0:
- LagartoBasedHtmlParser;
- JTidyHTMLParser;
- RegexpHTMLParser;
- JsoupBasedHtmlParser.
Парсери розбирають стартові сторінки різних веб-сайтів:
- stackoverflow.com;
- habrahabr.ru;
- yandex.ru;
- mos.ru;
- jmeter.apache.org;
- google.ru;
- linkedin.com;
- github.com.
основа тестування
Основою послужили зміни в Apache.JMeter 3.0, див. http://jmeter.apache.org/changes.html .
Витяги зі списку змін
Core improvements
Dependencies refresh
Deprecated Libraries dropped or replaced by up to date ones:
- htmllexer, htmlparser removed
- jdom removed
Вилучений парсер htmlparser і більш невживана бібліотека jdom.
Protocols and Load Testing improvements
Parallel Downloads is now realistic and scales much better:
- Parsing of CSS imported files (through @import) or embedded resources (background, images, ...)
Додано новий парсер для CSS-файлів, будуть вилучатись посилання на інші CSS-файли (через @import) і посилання на ресурси, зазначені в CSS-файлах: фонові зображення, картинки, ...
Incompatible changes
- Since version 3.0, the parser for embedded resources (replaced since 2.10 by Lagarto based implementation) which relied on the htmlparser library (HtmlParserHTMLParser) has been dropped along with its dependencies.
- The following jars have been removed:
Вилучений парсер htmlparser і що більше не використовуються бібліотеки htmllexer і jdom.
Improvements
HTTP Samplers and Test Script Recorder
- Bug 59036 - FormCharSetFinder: Use JSoup instead of deprecated HTMLParser
- Bug 59033 - Parallel Download: Rework Parser classes hierarchy to allow plug-in parsers for different mime types
- Bug 59140 - Parallel Download: Add CSS Parsing to extract links from CSS files
Для пошуку аттрибута accept-charset в тегах form тепер використовується JSoup замість вилученого HTMLParser [Bug 59036]. Реалізовано парсер CSS-файлів [Bug 59140] і цей парсер використовується за умовчанням [Bug 59033].
цілі тестування
Порівняти роботу всіх доступних парсеров. Зокрема порівняти між собою парсери версій 2.13 і 3.0, переконатися, що завантаження вбудованих ресурсів стала реалістичніше і краще.
стратегія
Етап 1:
- Виконати завантаження стартових сторінок списку сайтів використовуючи всі 5 парсеров Apache.JMeter 2.13 і записати логи.
- Виконати завантаження стартових сторінок списку сайтів використовуючи всі 4 парсеру Apache.JMeter 3.0 і записати логи.
- Проаналізувати логи роботи Apache.JMeter і порівняти їх між собою. Оцінити, чи стала завантаження вбудованих ресурсів краще, розширився чи перелік завантажуються вбудованих ресурсів.
Етап 2:
- Виконати завантаження стартових сторінок списку популярних сайтів, використовуючи Google Chrome і сервіс webpagetest.org.
- Проаналізувати звіти з webpagetest.org і порівняти їх з результатами аналізу логів Apache.JMeter. Оцінити, реалістичність завантаження вбудованих ресурсів.
Підхід до тестування
Щоб точно визначити скільки запитів надсилається під час відкриття сторінки сайту з Apache.JMeter всі запити логіруются:
- View Results Tree - стандратний логгер, логирование в XML-формат з логування підзапитів, XML-лог буде використовуватися для з'ясування деталей запитів / відповідей / помилок;
- CsvLogWriter - кастомний логгер https://github.com/pflb/Jmeter.Plugin.CsvLogWriter , Логирование в CSV-формат з логування підзапитів, CSV-лог буде використовуватися для програмного підрахунку статистики по роботі різних парсеров;
- виконується тільки кількісна оцінка, адреси підзапитів списках не порівнювати.
Щоб мати можливість згрупувати запити за версіями Apache.JMeter, парсером і сайтам, в лог будуть записуватися додаткові змінні для кожного запиту:
- siteKey - тестований сайт;
- jmeterVersion - версія Apache.JMeter;
- htmlParser - назва html-парсера, використовуваного в даний момент.
результати
Оцінка поліпшення роботи парсеров для версії 3.0 в порівнянні з версією 2.13
Кардинальних поліпшень повноти розбору html-сторінок немає, є погіршення.
Істотна відмінність - в парсером для Apache.JMeter 3.0 є рекурсивна завантаження сторінки промо-матеріалів браузера Яндекс Браузер. Це проявляється при завантаженні https://yandex.ru/ .
Сайти з малою кількістю контенту - хороший результат
На простих сайтах, таких як jmeter.apache.org, все парсери працюють однаково. Створюючи таку саму кількість підзапитів, яке створюється браузером. Якість роботи парсеров для jmeter.apache.org - ідеально, 100%.
Сайти з великою кількістю контенту - поганий результат
Але на такому сайті як mos.ru, парсери знайдуть в середньому 22 посилання на вбудовані ресурси, тоді як повне завантаження сторінки із завантаженням всіх вбудованих ресурсів браузером - 144 запиту. Якість низька.
Аналогічно на сайті habrahabr.ru, парсер Lagardo з Apache.JMeter 3.0 знайде 55 посилань, тоді як браузер зробить 117 підзапитів. Якість - 47,01%. Задовільну якість повноти вилучення посилань на вбудовані ресурси.
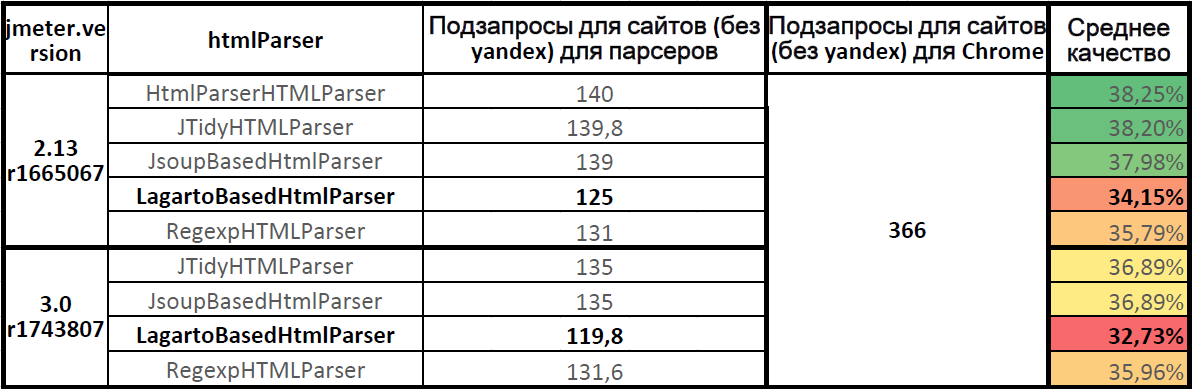
Кількість підзапитів при використанні різних парсеров
Таблиця на Google Docs: JMeter.HtmlParser.Compare (верхня таблиця) .
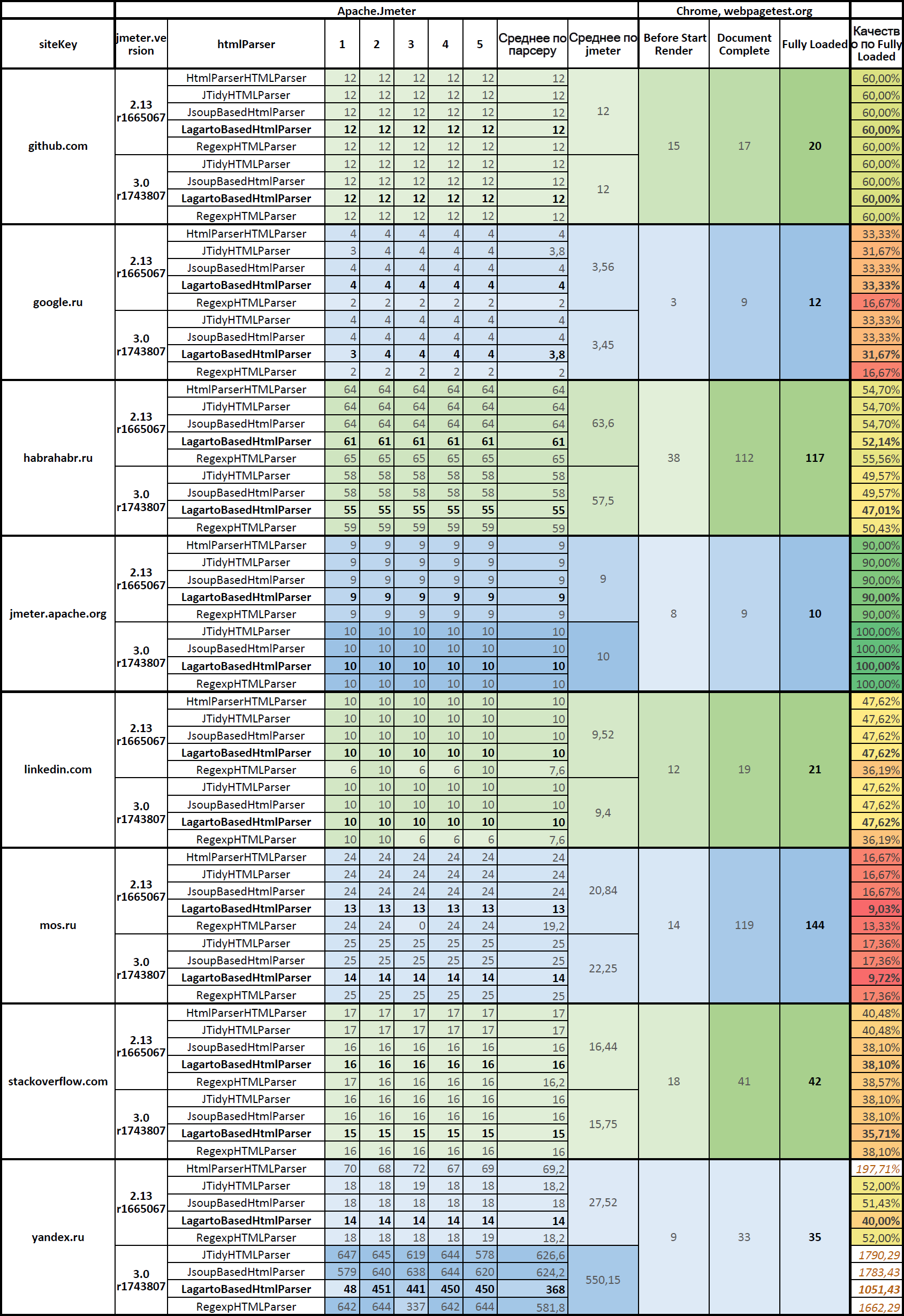
Статистика роботи Apache.JMeter в розрізі версій і html-парсеров і її порівняння з роботою Google Chrome
Опис стовпців:
- Before Start Render - кількість підзапитів, зроблених браузером, до моменту початку відображення вмісту сторінки. Це html-розмітка, основні js і css-файли, основні зображення.
- Document Complete - кількість підзапитів, зроблених браузером, на момент повного завантаження документа. Тут уже завантажилися всі ресурси сторінки.
- Fully Loaded - кількість підзапитів, зроблених браузером, на момент коли відпрацював javascript, коли загрузилось все.
Хорошим результатом роботи парсеров буде, якщо підзапитів буде стільки ж, скільки браузер Google Chrome робить на момент Document Complete, а відмінним - на момент Fully Loaded. Мірилом реалістичності роботи Apache.JMeter при використанні конкретного парсеру будемо вважати близькість кількості підзапитів до кількості підзапитів, виконуваних браузером на момент Fully Loaded.
Якщо виключити результати тестування сайту yandex.ru, де:
- парсинг йде в рекурсію роблячи знову і знову запити до yandex.ru поки глибина рекурсії не досягає максимального рівня і завершується помилкою:
java.lang.Exception: Maximum frame / iframe nesting depth exceeded
І за мірило якості роботи парсеров прийняти кількість підзапитів на момент Fully Loaded, то отримаємо таку таблицю середньої якості роботи парсеров.
Середня якість роботи парсеров
Таблиця на Google Docs: JMeter.HtmlParser.Compare (нижня таблиця) .
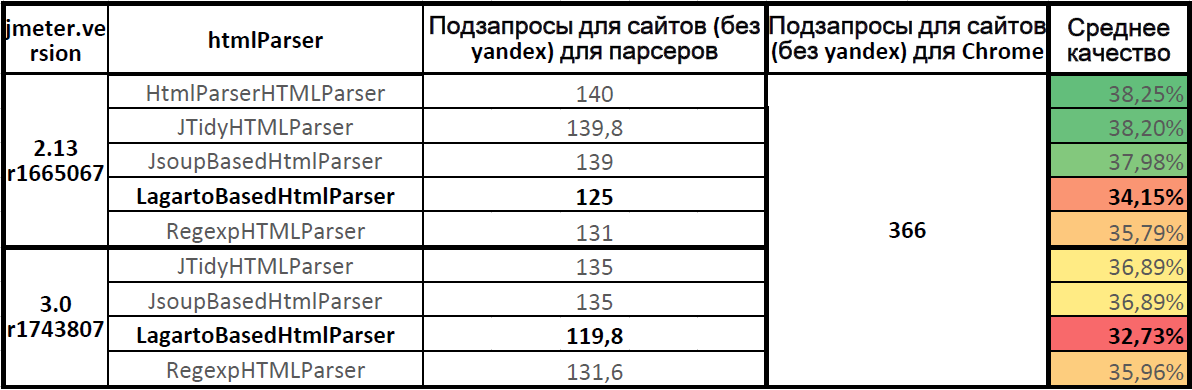
Середня якість роботи парсеров (для семи сайтів, без yandex.ru)
Найточніший парсер HTMLParser в Apache.JMeter 2.13. У Apache.JMeter 3.0 парсери Jsoup і JTidy показали однакову якість. Парсер Lagarto відстає від лідерів. Повнота парсинга для парсера Lagarto в Apache.JMeter 3.0 знизилася в порівнянні з Apache.JMeter 2.13.
Якість роботи парсера Lagarto на актуальній версії Apache.JMeter 3.0 склало 32,73%, лише третина всіх підзапитів була послана, дві третини навантаження на статику не було подано.
Детальний аналіз пропущених посилань при роботі Apache.JMeter 3.0 сайта habrahabr.ru
Таблиця на Google Docs: Пропущені дефолтних парсером Apache.JMeter 3.0 посилання на habrahabr.ru 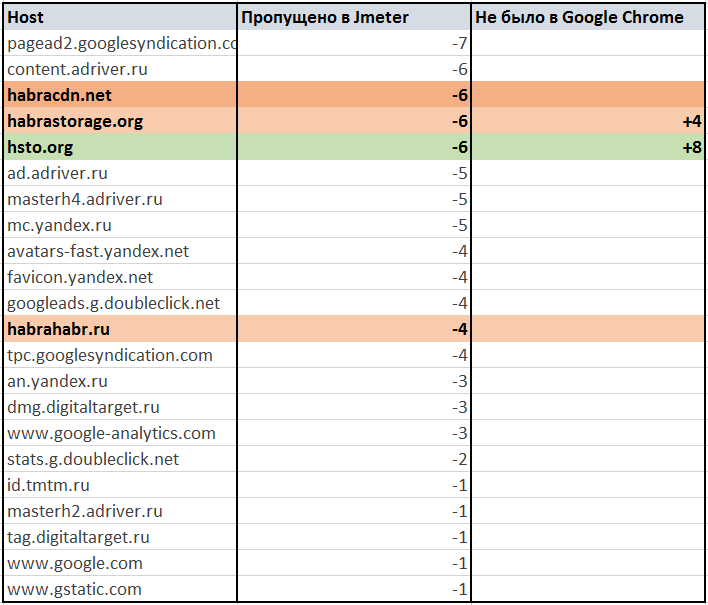
Пропущені Apache.JMeter 3.0 посилання при розборі habrahabr.ru
Пропущено багато рекламних матеріалів і статистики. І це добре.
Вище вже обговорювалося, що оцінювати буду тільки кількісні характеристики. За числах виходить, що якість вилучення посилань на вбудовані ресурси низька. Детальний аналіз може показати, що саме було пропущено. Може виявитися, що це реклама і контент зі сторонніх ресурсів, який необов'язково вантажити в рамках навантажувального тестування конкретного сайту.
Список і їх обробка
Вихідні дані
Всі логи доступні за посиланням: https://drive.google.com/drive/folders/0B5nKzHDZ1RIiVkN4dDlFWDR1ZGM .
звіти WebPageTest.org
зображення звітів
З значень колонок Document Complete і Fully Loaded потрібно виключити один запит (кореневої), щоб отримати кількість підзапитів.
Список Apache.JMeter
Для обробки використовуються csv-логи, сформовані плагіном CsvLogWriter:
Сторонній плагін використовується, щоб в csv-лог потрапили запити на embedded-ресурси.
В результаті роботи CsvLogWriter формується лог, в список колонок якого входять:
- timeStamp - момент часу;
- URL - адреса запиту;
- elapsed - тривалість отримання відповіді на запит;
- bytes - розмір відповіді;
- siteKey - використовуваний сайт;
- htmlParser - назва використовуваного;
- jmeterVersion - використовувана версія Apache.JMeter;
- i - номер ітерації тестування.
Автоматизація обробки балок
Аггрегаціі csv-логів Apache.JMeter виконується за допомогою pandas ось таким кодом на python:
import pandas as pd
import codecs
from os import listdir
import numpy as np
# Настройки - каталог з балками і налаштування зчитування логів.
dirPath = «D: /project/jmeter.htmlParser.3.0.vs.2.13/logs»
read_csv_param = dict (index_col = [ 'timeStamp'],
low_memory = False,
sep = ";",
na_values = [ '', ", 'null'])
# Отримання списку csv-файлів в каталозі з балками.
files = filter (lambda a: '.csv' in a, listdir (dirPath))
# Читання вмісту всіх csv-файлів в DataFrame dfs.
csvfile = dirPath + «/» + files [0] print (files [0])
dfs = pd.read_csv (csvfile, ** read_csv_param)
for csvfile in files [1:]:
print (csvfile)
tempDfs = pd.read_csv (dirPath + «/» + csvfile, ** read_csv_param)
dfs = dfs.append (tempDfs)
# Dfs.to_excel (dirPath + «/total.xlsx»)
# Прибрати з вибірки все JSR223, по ним статистику будувати не треба, залишити тільки HTTP Request Sampler.
# У JSR223 URL порожній, у HTTP-запитів URL вказано.
dfs = dfs [(pd.isnull (dfs.URL) == False)]
# Зведена таблиця за кількістю підзапитів, зберігається в report.subrequests.html - основний результат роботи.
# З кількості запитів видаляється один запит, щоб виключити кореневої запит.
# Мета даного дослідження - підрахунок кількості підзапитів, тому кореневої виключається.
pd.pivot_table (dfs,
index = [ 'siteKey', «jmeterVersion», «htmlParser»],
values = "URL",
columns = [ «i»],
aggfunc = lambda url: url.count () - 1) .to_html (dirPath + «/report.subrequest.count.html»)
Рекурсивна завантаження на yandex.ru
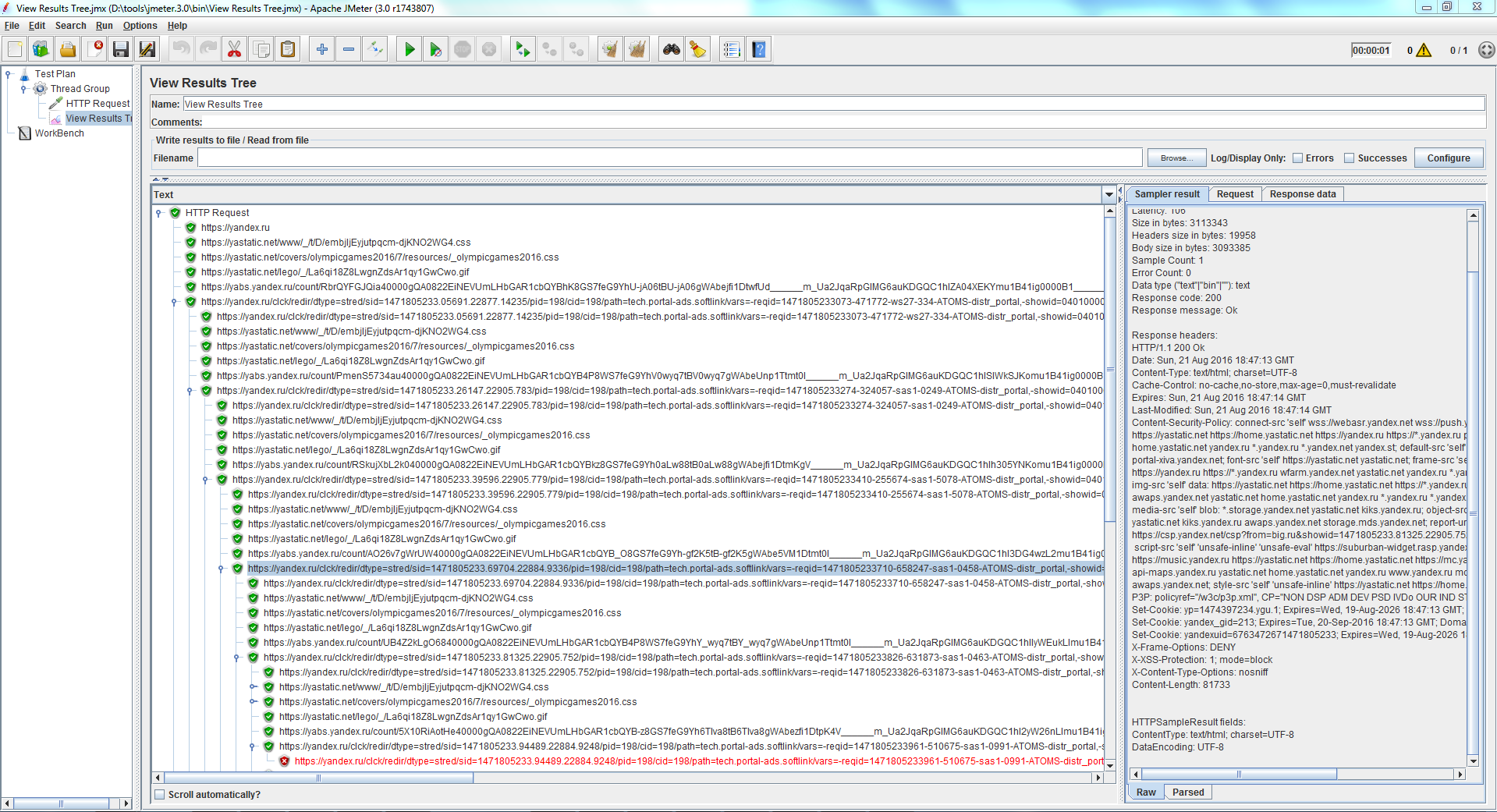
Рекурсивна завантаження вбудованих ресурсів для актуальної версії Apache.JMeter 3.0 з настройками за замовчуванням (html-парсер Lagarto) на сайті yandex.ru
Як видно:
- Apache.JMeter знаходить і переходить за посиланням https://yandex.ru/clck/redir/dtype=stred....7004fcb3793e79bb1ac9e&keyno=12
- Потім знаходить нову унікальну посилання https://yandex.ru/clck/redir/dtype=stred....cd1c46cad58fbfe2f61&keyno=12
- І так далі, йде в рекурсію.
В даному випадку це картинка всередині посилання на завантаження Яндекс браузера:
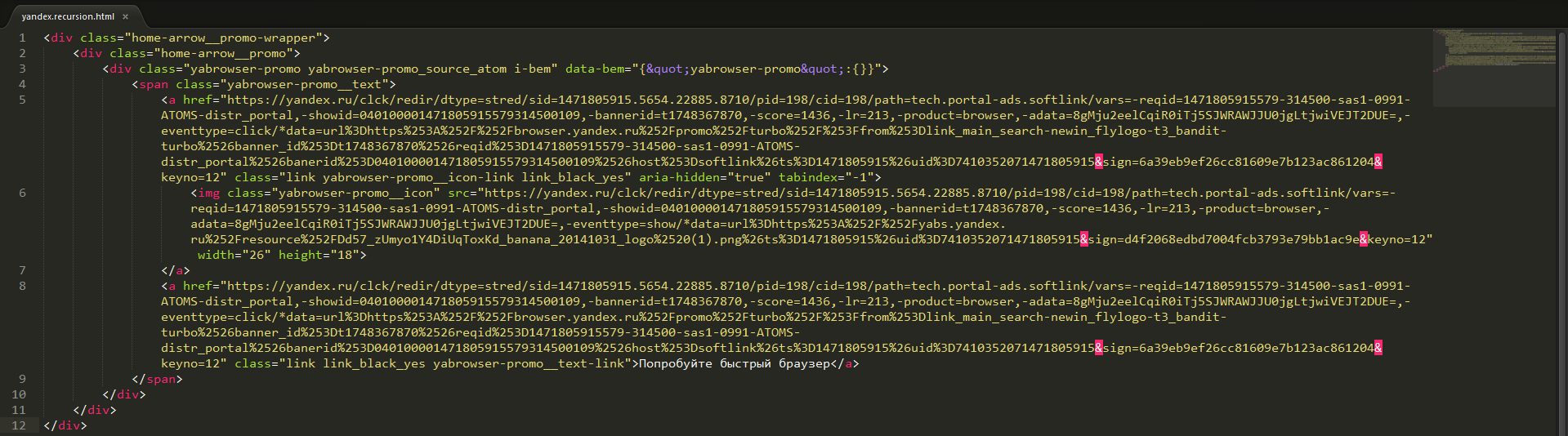
Фрагмент html-коду сайту yandex.ru обробка якого додає новий крок рекурсії, посилання і картинка для скачування Яндекс браузера
Картинку парсер знаходить. JMeter пробує її завантажити, у відповідь отримує html-сторінку, там знову посилання на картинку і інші посилання. І все повторюється. Поведінка Apache.JMeter коректне.
А в Apache.JMeter 2.13 рекурсія просходит тільки на парсером HtmlParser, здогадки чому не відбувається на інших:
- є обмеження на довжину посилань, і за рахунок відсікання унікального закінчення заслання рекурсії не відбувається;
- або в Apache.JMeter 2.13, щось неправильно працює в парсером;
- або в Apache.JMeter 2.13, щось працює навпаки правильно - куки, ще щось і сам сервер Яндекса відповідає йому так, щоб той не йшов в рекурсію, наприклад, відповідає картинкою на запит картинки, а не нової html-сторінкою.
Гадати не буду. Здається безвихідна ситуація. Але таких ситуацій не буває. Завжди є рішення.
Наприклад, можна спробувати в якості User-Agent вказати Яндекс Браузер. Тоді сервер, напевно, не покаже картинку для скачування браузера, або на запит картинки буде відповідати картинкою, і рекурсії не буде. Це здогад, не перевіряв її.
Зараз в скрипті був зазначений User-Agent для Google Chrome для синхронності з роботою webpagetest.org, і сервер, дивлячися, не свій браузер, мабуть, пропонує посилання на свій.
Склад проекту
- jmeter.testfile.jmx - тестовий скрипт для Apache.JMeter 2.13 і Apache.JMeter 3.0 приймає на вхід параметри:
- URL - адреса тестованого сайту, наприклад, https://yandex.ru/ ;
- siteKey - рядок по якій буде здійснюватися угруповання записів в логах, наприклад, yandex.ru;
- loopCount - кількість ітерацій тесту, використовується кілька ітерацій через те, що робота веб-сайтів може бути нестабільної;
- htmlParser.className - парсер для вилучення посилань на вбудовані ресурси;
- для роботи скрипта необхідно завантажити і встановити додатковий плагін CsvLogWriter .
- jmeter.3.0.bat - командний файл запуску тесту для Apache.JMeter 3.0, тут задається шлях до папки / bin / Apache.JMeter 3.0, шлях до тестового скрипту jmeter.testfile.jmx, опції запуску тесту, а також список htmlParser десятків перевірка роботи яких виконується;
- jmeter.2.13.bat - командний файл запуску тесту для Apache.JMeter 2.13, тут задається шлях до папки / bin / Apache.JMeter 2.13, шлях до тестового скрипту jmeter.testfile.jmx, опції запуску тесту, а також список htmlParser десятків перевірка роботи яких виконується;
- test.bat - командний файл запуску тесту на двох версіях Apache.JMeter, 2.13 і 3.0, файл містить кількість ітерацій тестування та адреси тестованих сайтів. Файл викликає файли jmeter.2.13.bat і jmeter.3.0.bat;
- jmeter.3.0.vs.jmeter.2.13.ipynb - блокнот для jupyter для аналізу логів роботи Apache.JMeter;
- statistics.xlsx - таблиця зі статистикою по роботі парсеров, результат дослідження.
Тест легко змінити під себе, вказати свої сайти і потрібну кількість ітерацій. Всі настройки задаються у файлі test.bat.
Файл test.bat з основними настройками тесту
CALL jmeter.2.13.bat http://stackoverflow.com/ 5 stackoverflow.com
CALL jmeter.2.13.bat https://habrahabr.ru/ 5 habrahabr.ru
CALL jmeter.2.13.bat https://yandex.ru/ 5 yandex.ru
CALL jmeter.2.13.bat https://www.mos.ru/ 5 mos.ru
CALL jmeter.2.13.bat http://jmeter.apache.org/ 5 jmeter.apache.org
CALL jmeter.2.13.bat https://www.google.ru/ 5 google.ru
CALL jmeter.2.13.bat https://www.linkedin.com/ 5 linkedin.com
CALL jmeter.2.13.bat https://github.com/ 5 github.com
REM === === ===
CALL jmeter.3.0.bat http://stackoverflow.com/ 5 stackoverflow.com
CALL jmeter.3.0.bat https://habrahabr.ru/ 5 habrahabr.ru
CALL jmeter.3.0.bat https://yandex.ru/ 5 yandex.ru
CALL jmeter.3.0.bat https://www.mos.ru/ 5 mos.ru
CALL jmeter.3.0.bat http://jmeter.apache.org/ 5 jmeter.apache.org
CALL jmeter.3.0.bat https://www.google.ru/ 5 google.ru
CALL jmeter.3.0.bat https://www.linkedin.com/ 5 linkedin.com
CALL jmeter.3.0.bat https://github.com/ 5 github.com
Далі результати можна вставляти з Excel-файл з налаштованими формулами і отримувати наочну таблицю результатів.
Можна спробувати доопрацювати парсери, і за схожою методикою відстежувати поліпшення якості розбору embedded-ресурсів.
висновки
Особливою практичної цінності в статті немає. Але деякі корисні висновки зробити можна:
- парсер в середньому отримує посилання тільки на третину ресурсів;
- парсери працюють майже однаково, а значить можна застосовувати будь-який;
- парсери заточені під роботу з простими сайтами, такими як jmeter.apache.org;
- на сайтах з великою кількістю вмісту парсери працюють значно гірше реального браузера;
- повнота завантаження вбудованих ресурсів в новій версії JMeter незначно знизилася, а не зросла (на вибраних сайтах);
- продемонстровано прикладне використання плагіна CsvLogWriter, логірующего запити до embedded-ресурсів в csv-лог, який зробила моя колега Олександра Перевозчикова;
- за допомогою bat-файлів, передачі парамеров JMeter через командний рядок, логування змінних і обробки csv-логів за допомогою pandas можна тестувати сам інструмент тестування, методика відпрацьована, см. проект на github:
Джерело статті: habrahabr.ru .
І тут постало питання, а як це якість, як його виміряти для різних сайтів, яким воно було і яким стало?