Реалізація дерева пошуку - Problem Solving with Algorithms and Data Structures
Двійкові дерева пошуку покладаються те, що ключі менше батьківського знаходяться в лівому поддереве, а більше - в правом. Ми будемо називати це bst-властивістю (від англ. Binary search tree - прим. Перекладача). В процесі реалізації описаного вище інтерфейсу Map воно стане нашим вірним провідником. Малюнок 1 ілюструє це властивість довічних дерев пошуку, показуючи ключі без асоційованих з ними значень. Зверніть увагу: їм володіють і вузли-нащадки, і вузли-предки. Всі ключі в лівих Піддерево менше ключа кореня, а в правих - більше його. 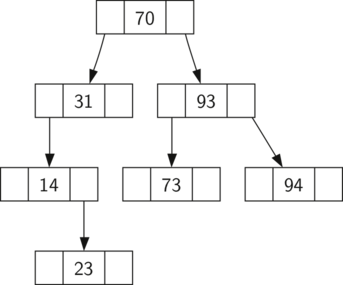
Малюнок 1: Просте бінарне дерево пошуку
Тепер, коли ви знаєте, що таке бінарне дерево пошуку, можна розглянути процес його створення. Дерево пошуку на малюнку 1 містить вузли, що з'явилися після вставки наступних ключів в такому порядку: \ (70,31,93,94,14,23,73 \). Так як 70 - перший вставляється в дерево значення, то це корінь. Число 31 менше 70-и, тому воно йде в ліве піддерево. 93 навпаки більше - і вставляється в праве піддерево. Тепер у нас заповнені два рівня з трьох, так що наступний ключ повинен стати нащадком 31 або 93. 94 більше, ніж 70 і 93, тому ми робимо його правим нащадком 93. Аналогічно, 14 менше і 70, і 31, отже, воно йде в ліве піддерево 31. 23 менше, ніж 31, так що воно теж повинно бути в лівому поддереве 31. Однак, це число більше 14, отже, стає його правим нащадком.
Для реалізації двійкового дерева пошуку ми використовуємо вузли та посилання (аналогічно зв'язаний список і дереву вираження). Однак, оскільки нам треба бути готовими використовувати двійкове дерево пошуку і коли воно порожнє, ми створимо два класи. Перший назвемо BinarySearchTree, а другий - TreeNode. BinarySearchTree матиме посилання на об'єкт TreeNode, який є коренем дерева. У більшості випадків зовнішні методи, певні в зовнішньому класі, просто перевіряють дерево на порожнечу. Якщо у нього є вузли, то запит просто передається в приватний метод з BinarySearchTree, який приймає корінь як параметр. У разі, коли дерево порожньо або ми хочемо видалити ключ з кореня, необхідно виконати спеціальні дії. Код для конструктора класу BinarySearchTree і декількох інших різних функцій показаний в лістингу 1 .
лістинг 1
class BinarySearchTree: def __init__ (self): self. root = None self. size = 0 def length (self): return self. size def __len__ (self): return self. size def __iter__ (self): return self. root. __iter__ ()
Клас TreeNode надає безліч допоміжних функцій, які значно полегшують роботу BinarySearchTree. Конструктор TreeNode разом з цими функціями показаний в лістингу 2 . З нього видно, що більшість додаткових функцій допомагають класифікувати вузол відповідно до його положенням як нащадка (лівого або правого) і типом його дітей.
Так само клас TreeNode явно відстежує батька, як атрибут кожного вузла. Ви зрозумієте важливість цього, коли ми будемо обговорювати реалізацію оператора del.
Інший цікавий аспект TreeNode в лістингу 2 полягає в використанні опціональних параметрів Python. Вони дозволяють нам спростити його створення у відповідності з різними обставинами. Іноді ми захочемо сконструювати новий об'єкт TreeNode, має і parent, і child. З уже існуючими нащадком і предком їх можна просто передати, як параметри. Наступного разу ми створимо TreeNode з парою ключ-значення, не передаючи при цьому ні parent, ні child. В цьому випадку для параметрів будуть використовуватися значення за замовчуванням.
лістинг 2
class TreeNode: def __init __ (self, key, val, left = None, right = None, parent = None): self.key = key self.payload = val self.leftChild = left self.rightChild = right self.parent = parent def hasLeftChild (self): return self.leftChild def hasRightChild (self): return self.rightChild def isLeftChild (self): return self.parent and self.parent.leftChild == self def isRightChild (self): return self.parent and self.parent.rightChild == self def isRoot (self): return not self.parent def isLeaf (self): return not (self.rightChild or self.leftChild) def hasAnyChildren (self): return self.rightChild or self.leftChild def hasBothChildren (self): return self.rightChild and self.leftChild def replaceNodeData (self, key, value, lc, rc): self.key = key self.payload = value self.leftChild = lc self.rightChild = rc if self .hasLeftChild (): self.leftChild.parent = self if self.hasRightChild (): self.rightChild.parent = self
Тепер, коли у нас є обгортка BinarySearchTree і клас TreeNode, прийшов час написати метод put, який дозволить будувати двійкові дерева пошуку. Він буде належати класу BinarySearchTree. Метод буде виконувати перевірку на наявність кореня дерева, а в разі відсутності останнього створювати об'єкт TreeNode і встановлювати його, як кореневий вузол. В іншому випадку put викличе приватну рекурсивную допоміжну функцію _put для пошуку місця в дереві за наступним алгоритмом:
- Починаючи від кореня, проходимо за допомогою бінарного дереву, порівнюючи новий ключ з ключем поточного вузла. Якщо перший менше другого, то йдемо в ліве піддерево. Навпаки - в праве.
- Коли не залишилося лівих або правих нащадків для пошуку - ми знайшли позицію для установки нового вузла.
- Щоб додати вузол в дерево, створюємо новий об'єкт TreeNode і поміщаємо його на знайдене за попередні кроки місце.
лістинг 3 показує код Python для вставки нового вузла в дерево. Функція _put написана рекурсивно і слід описаним вище пунктам. Відзначте, що коли в дерево вставляється новий нащадок, currentNode передається як батько нового поддерева.
Однією з серйозних проблем нашого реалізації є те, що дублікати ключів не обробляються правильним чином. У нас дубль створить новий вузол з точно таким же значенням ключа і помістить його в праве піддерево вузла з оригінальним ключем. В результаті новий вузол ніколи не буде виявлений в процесі пошуку. Для управління вставкою дублікатів ключів є спосіб краще: зробити так, щоб значення, асоційоване з новим ключем, замінювало старе. Ми залишаємо вам виправлення цього недоліку в якості вправи.
лістинг 3
def put (self, key, val): if self. root: self. _put (key, val, self. root) else: self. root = TreeNode (key, val) self. size = self. size + 1 def _put (self, key, val, currentNode): if key <currentNode. key: if currentNode. hasLeftChild (): self. _put (key, val, currentNode. leftChild) else: currentNode. leftChild = TreeNode (key, val, parent = currentNode) else: if currentNode. hasRightChild (): self. _put (key, val, currentNode. rightChild) else: currentNode. rightChild = TreeNode (key, val, parent = currentNode)
Визначивши метод put, можна легко перевантажити оператор [] для присвоєння за допомогою виклику методу __setitem__ (див. лістинг 4 ). Це дозволить нам писати вирази виду myZipTree [ 'Plymouth'] = 55446, як для словників Python.
лістинг 4
def __setitem__ (self, k, v): self. put (k, v)
малюнок 2 ілюструє процес вставки нового вузла в двійкове дерево пошуку. Злегка затінені вузли - це ті, що були відвідані в процесі вставки.
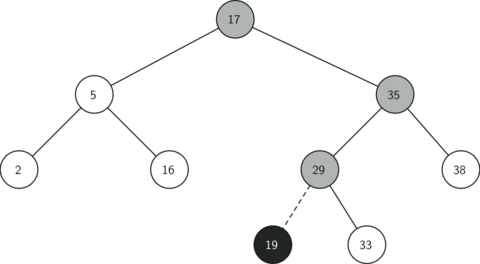
Малюнок 2: Вставка вузла з ключем, рівним 19.
самоперевірка
Q-66: Яке з показаних дерев буде правильним двійковим деревом пошуку, ключі в яке вставлялися в наступному порядку: 5, 30, 2, 40, 25, 4?
Оскільки дерево вже сконструйовано, то наступне завдання - реалізувати пошук значення по заданому ключу. Метод get простіше put, тому що просто робить рекурсивний пошук, поки не дійде до листового вузла або не знайдете шукане. Коли ключ знайдеться, збережене в вузлі значення буде повернуто.
лістинг 5 демонструє код для get, _get і __getitem__. Пошук в методі _get``іспользует ту ж логіку для вибору правого або лівого нащадка, що і `` _put. Зверніть увагу, _get повертає в get об'єкт TreeNode. Це дозволяє використовувати _get як гнучкий допоміжного методу для інших методів BinarySearchTree, яким, крім корисного навантаження, можуть знадобитися і інші дані з TreeNode.
Реалізувавши метод __getitem__, можна писати оператори Python, виглядають так, ніби ми маємо доступ до словника, коли за фактом використовується двійкове дерево пошуку. Наприклад, z = myZipTree [ 'Fargo']. Як ви бачите, все, що робить __getitem__, - це викликає get.
лістинг 5
def get (self, key): if self. root: res = self. _get (key, self. root) if res: return res. payload else: return None else: return None def _get (self, key, currentNode): if not currentNode: return None elif currentNode. key == key: return currentNode elif key <currentNode. key: return self. _get (key, currentNode. leftChild) else: return self. _get (key, currentNode. rightChild) def __getitem__ (self, key): return self. get (key)
З використанням get можна реалізувати операцію in, написавши метод __contains__ для BinarySearchTree. Він буде просто викликати get і видавати True, якщо get повертає значення, чи False в іншому випадку. Код для __contains__ показаний в лістингу 6 .
лістинг 6
def __contains__ (self, key): if self. _get (key, self. root): return True else: return False
Нагадаємо, що __contains__ перевантажує оператор in і дозволяє писати код на зразок
if 'Northfield' in myZipTree: print ( "oom ya ya")
На завершення звернемо нашу увагу на найбільш складний метод для двійкового дерева пошуку - видалення ключа (див. лістинг 7 ). Першим завданням буде пошук в дереві видаляється. Якщо дерево має більше одного вузла, то для цього використовується метод _get. Якщо ж воно складається з єдиного вузла, то це має на увазі видалення кореня. Однак, перевірити кореневої ключ на відповідність удаляемому об'єкту все ж необхідно. В обох випадках, якщо ключ не знайдений, то оператор del видає помилку.
лістинг 7
def delete (self, key): if self.size> 1: nodeToRemove = self._get (key, self.root) if nodeToRemove: self.remove (nodeToRemove) self.size = self.size-1 else: raise KeyError ( 'Error, key not in tree') elif self.size == 1 and self.root.key == key: self.root = None self.size = self.size - 1 else: raise KeyError ( 'Error, key not in tree ') def __delitem __ (self, key): self.delete (key)
Після того, як ми знайшли ключ видаляється значення, існує три варіанти, кожен з яких слід розглянути окремо:
- Видаляється вузол не має нащадків (див. малюнок 3 ).
- У видаляється вузла є тільки один нащадок (див. малюнок 4 ).
- У видаляється вузла є обидва нащадка (див. малюнок 5 ).
У першому випадку все очевидно (див. лістинг 8 ). Якщо поточний вузол не має нащадків, то все, що від нас вимагається, - це видалити його і посилання на нього у його батька. Ось код для цього:
лістинг 8
if currentNode. isLeaf (): if currentNode == currentNode. parent. leftChild: currentNode. parent. leftChild = None else: currentNode. parent. rightChild = None 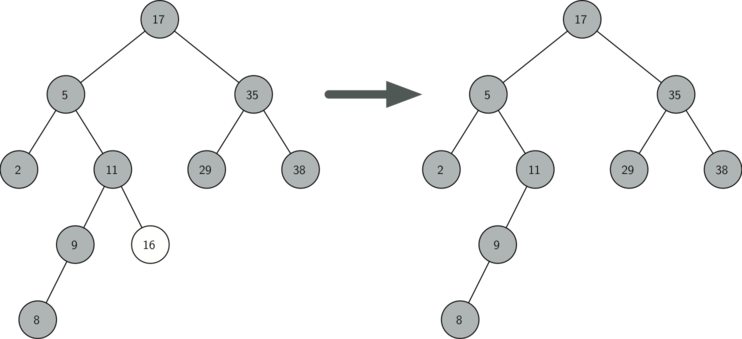
Малюнок 3: Видалення вузла 16, що не має нащадків
Другий випадок набагато складніше (див. лістинг 9 ). Якщо у вузла всього один нащадок, то ми просто допоможемо йому зайняти місце батька. Код для цього показаний в наступному лістингу. З нього ви можете бачити, що є шість випадків для розгляду. Оскільки вони симетричні для обох дітей, ми обговоримо тільки варіант, коли вузол має лівого нащадка. Процес пошуку рішення наступний:
- Якщо поточний вузол - лівий нащадок, то потрібно всього лише оновити батьківську посилання на нього у предка, а потім обновити посилання його нащадка, щоб вона вказувала на нового батька.
- Якщо поточний вузол - правий нащадок, то ми оновлюємо батьківську посилання його нащадка, щоб вона вказувала на предка поточного вузла, а потім - посилання на правого нащадка у батька поточного вузла.
- Якщо поточний вузол предка не має, то він повинен бути коренем. В цьому випадку ми просто замінюємо дані key, payload, leftChild і rightChild, викликавши для кореня метод replaceNodeData.
лістинг 9
else: # this node has one child if currentNode.hasLeftChild (): if currentNode.isLeftChild (): currentNode.leftChild.parent = currentNode.parent currentNode.parent.leftChild = currentNode.leftChild elif currentNode.isRightChild (): currentNode.leftChild .parent = currentNode.parent currentNode.parent.rightChild = currentNode.leftChild else: currentNode.replaceNodeData (currentNode.leftChild.key, currentNode.leftChild.payload, currentNode.leftChild.leftChild, currentNode.leftChild.rightChild) else: if currentNode. isLeftChild (): currentNode.rightChild.parent = currentNode.parent currentNode.parent.leftChild = currentNode.rightChild elif currentNode.isRightChild (): currentNode.rightChild.parent = currentNode.parent currentNode.parent.rightChild = currentNode.rightChild else: currentNode .replaceNodeData (currentNode.rightChild.key, currentNode.rightChild.payload, currentNode.rightChild.leftChild, currentNode.rightChild.rightChild) 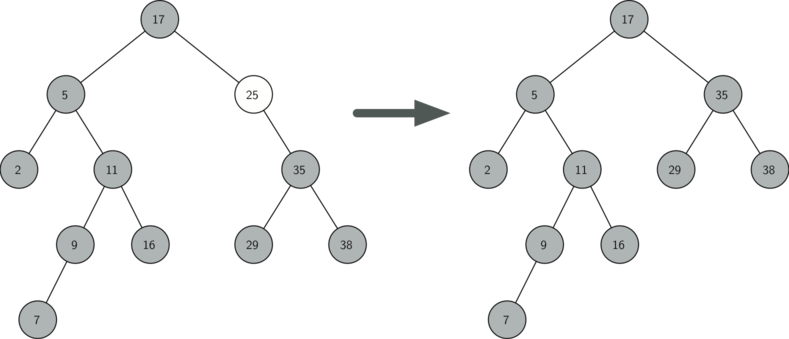
Малюнок 4: Видалення вузла 25, що має єдиного нащадка.
Третій випадок найбільш складний для обробки (див. лістинг 10 ). Якщо у вузла є обидва нащадка, то малоймовірно, що можна просто поставити їх на місце батька. Однак, ми можемо пройти пошуком по дереву і знайти вузол, здатний замінити той, який стоїть в списку на вибування. Нам потрібно, щоб цей вузол зберігав прийняті в довічним дереві пошуку відносини між існуючими правим і лівим піддеревами, тобто він буде мати наступний за величиною ключ. Ми назвемо такий вузол наступником і розглянемо спосіб знайти якомога швидше. Наступник гарантовано має не більше, ніж одного нащадка, так що ми знаємо, як можна його видалити з використанням двох уже розглянутих і написаних випадків. Як тільки наступник буде видалений, ми просто вставимо його в дерево на місце видаленого вузла.
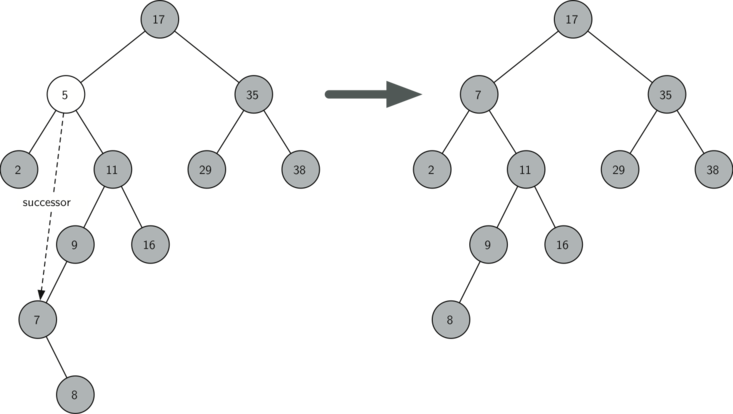
Малюнок 5: Видалення вузла 5, що має двох нащадків.
Код, що обробляє третій випадок, показаний в наступному лістингу. Зверніть увагу на використання допоміжних методів findSuccessor і findMin для пошуку наступника. Щоб його видалити, ми застосовуємо метод spliceOut. Причина, по якій це робиться, полягає в тому, що він йде точно в той вузол, що ми хочемо поєднати, і здійснює правильну заміну. Можна було б рекурсивно викликати delete, але це означає марнування часу на повторний пошук ключового вузла.
лістинг 10
elif currentNode.hasBothChildren (): #interior succ = currentNode.findSuccessor () succ.spliceOut () currentNode.key = succ.key currentNode.payload = succ.payload
Код для пошуку наступника показаний нижче (див. лістинг 11 ) І, як ви можете бачити, це метод класса``TreeNode``. Тут використовуються ті ж властивості довічних дерев пошуку, що і при роздруківці вузлів від меншого до більшого при симетричному обході. Ось три випадки, які слід розглянути при пошуку наступника:
- Якщо у вузла є правий нащадок, то наступник - найменший ключ в правому піддереві.
- Якщо у вузла немає правого нащадка і сам він - лівий нащадок батька, то наступником буде батько.
- Якщо вузол - правий нащадок свого батька і сам правого нащадка не має, то його наступником буде наступник батька (виключаючи сам цей вузол).
Перша умова - єдине має для нас значення при видаленні вузла з двійкового дерева пошуку. Однак, метод findSuccessor має ще одне застосування, яке буде досліджено в вправах в кінці цієї глави.
Метод findMin викликається для пошуку мінімального ключа в дереві. Вам слід самостійно переконатися, що мінімальний ключ в будь-якому довічним дереві пошуку - самий лівий з нащадків. Тому метод findMin всього лише слід по посиланнях leftChild до тих пір, поки не досягне вузла, що не має лівих нащадків.
лістинг 11
def findSuccessor (self): succ = None if self. hasRightChild (): succ = self. rightChild. findMin () else: if self. parent: if self. isLeftChild (): succ = self. parent else: self. parent. rightChild = None succ = self. parent. findSuccessor () self. parent. rightChild = self return succ def findMin (self): current = self while current. hasLeftChild (): current = current. leftChild return current def spliceOut (self): if self. isLeaf (): if self. isLeftChild (): self. parent. leftChild = None else: self. parent. rightChild = None elif self. hasAnyChildren (): if self. hasLeftChild (): if self. isLeftChild (): self. parent. leftChild = self. leftChild else: self. parent. rightChild = self. leftChild self. leftChild. parent = self. parent else: if self. isLeftChild (): self. parent. leftChild = self. rightChild else: self. parent. rightChild = self. rightChild self. rightChild. parent = self. parent
Нам залишилося розглянути останній метод інтерфейсу для двійкового дерева пошуку. Припустимо, ви просто хочете перебрати всі ключі в дереві по порядку. Це виразно те, що ми робимо зі словниками, так чому б не зробити це і з деревом? Ви вже знаєте, як обходити двоичное дерево по порядку з використанням алгоритму обходу inorder. Однак, написання ітератора Поремба трохи більше роботи, оскільки він повинен повертати тільки один вузол за кожен свій виклик.
Для створення ітератора Python є дуже продуманим функцію під назвою yield. Вона аналогічна return, що повертає значення зухвалому коду. Однак, yield так само робить додатковий крок, заморожуючи стан функції, щоб коли вона буде викликана в наступний раз, обчислення продовжилися з залишеного місця. Функція, що створює об'єкт, який може бути ітерованих, називається генератором функцій.
Код для ітератора inorder двійкового дерева показаний в наступному лістингу. Подивіться на нього уважніше: на перший погляд може здатися, ніби він не рекурсивний. Однак, згадайте, що __iter__ перевантажує опреацию for x in для ітерірованія. Так що насправді рекурсія тут є. Оскільки код рекурсівен для об'єктів TreeNode, метод __iter__ визначений в класі TreeNode.
def __iter __ (self): if self: if self.hasLeftChild (): for elem in self.leftChiLd: yield elem yield self.key if self.hasRightChild (): for elem in self.rightChild: yield elem
Зараз вам можете захотітися цілком завантажити файл, який містить повну версію класів BinarySearchTree і TreeNode.
Run Save Load Show in Codelens
(Completebstcode)
Це виразно те, що ми робимо зі словниками, так чому б не зробити це і з деревом?